
Después de conocer el Hardware y el Software, vamos a conocer como se comunican los sistemas informáticos, para ello, es importante conocer su lenguaje.
El sistema de numeración que los seres humanos utilizamos habitualmente es el sistema decimal. Es un sistema que usa diez dígitos para formar infinitos números (el 0,1,2,3,4,5,6,7,8 y el 9).
Pero en informática y electrónica se usa otro sistema de numeración, igual de válido que el decimal, llamado sistema binario (por que solo usa dos dígitos el 0 y el 1).
¿Por qué se usa este sistema de numeración en electrónica y en informática?
Los procesadores y memorias disponen de flip flops, dispositivos de dos estados (biestables), que sirven como memoria básica para las operaciones de lógica secuencial.
Como los flip flops tienen dos estados estables, se suelen usar en elementos de memoria como registros, para el almacenamiento de datos. Generalmente usamos registros en dispositivos electrónicos como computadoras.
Los estados se corresponden con:
- un nivel de tensión más bajo (entre 0 y 2,5V), que se denomina nivel BAJO (LOW)
- y un nivel de tensión más elevado (desde 2,5 a 5V), que se denomina nivel ALTO (HIGH).
Estos dos estados eléctricos para nosotros serán dos números posibles “0” y “1” que corresponden a los estados de interruptor “abierto” y “cerrado”.
Si detrás del interruptor tuviéramos unas lámparas conectadas, unas estarían encendidas y otras apagadas, según estuvieran los interruptores.
De esta forma podríamos decirle a un ordenador, formado solo por lámparas, cuando quiero que estén unas encendidas y otras apagadas.

Cada 0 o 1 del número en binario se llama bit y es la unida más pequeña de representación de información en un ordenador, que se corresponde con un dígito binario, 0 o 1.
La letra A ( y cualquier carácter) en este código se expresa con 8 bits : 10100001
Un byte = conjunto de 8 bits, que es lo que ocupa un número o un carácter (letra, o símbolo) en el sistema de codificación usado en informática.
En un byte podemos representar números desde el 0 hasta el 255, o mejor dicho desde el 00000000 hasta el 11111111 binario. Parece que la cosa se complica al aumentar el número de bits, y representar números más grandes empleando el sistema binario puede resultar bastante incómodo.

En informática podríamos asignar a cada letra o símbolo (caracteres) o número, un número en binario de 8 cifras (8 ceros y unos) y así obtener un código mediante el cual podamos entendernos con el ordenador. Este código de llama código ASCII:
Por ejemplo la letra A es el número 10100001.
Cuando apretamos la tecla de la letra A, le mandamos la información al ordenador su correspondiente código binario de 8 cifras, es decir el número (10100001) y el interpreta que le estamos diciendo que queremos que nos saque en la pantalla el símbolo de la letra A.
Fíjate en la tabla ASCII. Por ejemplo si le introduzco el número (instrucción en binario) 01001 le estoy diciendo que encienda las lámparas de la figura (la segunda y la última que valen 1). Podríamos decirle que si pasara esto nos mostrara en la pantalla la letra “A”, por ejemplo, en lugar de encender lámparas.
Así hablamos con nuestro ordenador.

¿Pero como almacena el ordenador la información?
Como hemos dicho representar números más grandes empleando el sistema binario puede resultar bastante incómodo.
Para facilitar las cosas apareció el sistema hexadecimal (hex), que representa con un solo dígito números desde el 0 hasta el 15, es decir, que es un sistema de base 16. Un solo dígito en hexadecimal puede representar un grupo de cuatro bits (denominado Nibble), lo cual simplifica notablemente la conversión de un sistema al otro, además de la representación de grandes números binarios.
Como la base del sistema hexadecimal es dieciséis, se requieren dieciséis dígitos diferentes para la escritura. Por eso, además de los diez dígitos del sistema decimal (9, 8, 7, 6, 5, 4, 3, 2, 1 y 0), se usan las primeras seis letras del alfabeto latino: A, B, C, D, E y F.
Representación de numero Binario (8 Bits) a Hexadecimal
| NIBBLE ALTO | NIBBLE BAJO | |
| BINARIO | 0001 | 1111 |
| HEXADECIMAL | 1 | F |
Para indicar que un valor esta escrito en hexadecimal, se utiliza el prefijo 0x (Por lo que este valor seria 0x1F)
- Dos digitos hex representan 8 bits y tienen un rango entre
0y255. - Cuatro digitos hex representan 16 bits y tienen un rango entre
0y65535. - Ocho digitos hex representan 32 bits y tienen un rango entre
0y4294967295.

Memoria RAM
- Es la memoria principal con la que se comunica el Procesador para realizar sus cálculos.
- Es rápida, pero volátil (pierde la información en cuanto se desconecta).
- Almacena el código (Código de Máquina) y los datos.
- La memoria principal es el conjunto de bytes (secuencia de bytes en hexadecimal), el el que cada byte esta identificado con un numero único, donde se almacena, conocido como su dirección.
- La primera dirección empieza en cero, y la ultima depende de la capacidad de l hardware y el software en uso. Las direcciones y valores se representan en hexadecimal.
- Otro concepto importante de la ingeniería inversa es la gestión de la memoria del ordenador. Para que un programa se ejecute, deben ser cargado en memoria primero.
- Una vez realizado es posible visualizar y modificar los datos de un programa y las instrucciones en la memoria porque la arquitectura de las máquinas IA-32 no impone ninguna restricción.

Ya hemos visto que un grupo de 8 bits se denomina byte, y que se podía representar con dos dígitos en hexadecimal.
Pues:
- a un grupo de 16 bits se le denomina word (palabra), dividiéndose en high byte y low byte.
- a un grupo de 32 bits se le denomina dword, dividiéndose en high word y low word.
- a un grupo de 64 bits se le denomina qword, dividiéndose en high dword y low dword.
En la memoria, los datos se almacenan en el formato little-endian (usada por procesadores Intel y AMD), es decir, un byte de orden inferior se almacena en la dirección más baja, y los bytes subsiguientes se almacenan en direcciones sucesivamente más altas en la memoria, a diferencia del formato big-endian (usada por Motorola y Apple), que almacena datos al contrario, es decir, un byte de orden inferior se almacena en la dirección más alta, y los bytes subsiguientes se almacenan en direcciones sucesivamente más bajas en la memoria.
Estructura de la memoria en Windows
La parte superior de la memoria esta reservada para el sistema operativo (como en todo sistema lógico, la parte superior o mas cercana de la memoria, esta reservada con procesos mas cercanos al núcleo de la estructura o hardware).
La parte inferior para la aplicación. En esta parte se encuentran:
- El Archivo de Imagen del Proceso de Mapeo en Memoria.
- DLL (Libreria), que utiliza.
- Regiones asignadas para los Datos (Pila).
- Regiones que comparten los procesos.
- El Process Enviroment Block (PEB)
El PEB es una estructura importante para el análisis de Malware ya que proporciona mucha información (lista de controladores de excepciones registradas, si el proceso se esta depurando, lista de módulos DLL cargados, parámetros, etc…).
La Pila o Stack:

La Pila es el espacio de memoria asignado para almacenar la memoria durante un espacio corto de tiempo, construida sobre una estructura LIFO (Last In First Out).
Los datos insertados el la última posición de la Pila (con la instrucción Push – insertar – en Ensamblador), son los que primero se pueden leer (con la instrucción Pop -sacar -).
La Pila se utiliza principalmente por las funciones de programa (con la instrucción de llamada Call), para guardar la dirección de retorno.
El registro ESP ( Extended Stack Pointer)
Apunta a la parte superior de la Pila, cuando un nuevo elemento se apila, aumenta el valor de ESP y viceversa.
Heap:
Es un espacio de memoria que permite la asignación dinámica de bloques de memoria de tamaño variable en tiempo de ejecución a diferencia de la Pila puede almacenar variables globales y variables locales grandes.
Datos:
Sección especifica de la memoria, que contiene los valores que utiliza cuando un programa se carga inicialmente. Estos valores se denominan estáticos porque no se pueden cambiar mientras se ejecuta el programa, o pueden ser llamados variables globales porque están a disposición de cualquier parte del programa.
Código:
Incluye las instrucciones extraídas dela CPU para ejecutar las tareas del programa. El código controla lo que el programa hace y como ejecuta las tareas programadas.

Registros de datos:
Los registros de datos consisten en cuatro registros de datos de 32 bits, que se utilizan para operaciones aritméticas, lógicas y de otro tipo. Los registros de datos se clasifican nuevamente en 4 tipos que son:


Registros de índice:
los bits de 16 bits situados más a la derecha de los registros de índice ESI* y EDI de 32 bits. SI y DI a veces se emplean en suma y otras en resta, así como para direccionamiento indexado.
SI (ESI* en 32 bits y RSI en 64 bits):
este registro de índice de origen se utiliza para identificar las direcciones de memoria en el segmento de datos al que se dirige DS. Por lo tanto, es sencillo acceder a ubicaciones de memoria sucesivas cuando incrementamos los contenidos de SI. Tiene un tamaño de 16 bits. En relación con el segmento de datos, tiene un desplazamiento.
DI (EDI en 32 bits y RDI en 64 bits):
La función de este registro de índice de destino es idéntica a la de SI. Las operaciones de cadena son una subclase de instrucciones que emplean DI para acceder a las direcciones de memoria especificadas por ES. Generalmente se utiliza como índice de destino para operaciones de cadena.
Registros de propósito especial:
Para almacenar datos de estado de la máquina y cambiar la configuración de estado, se emplean registros de propósito especial. En otras palabras, también se define como la CPU tiene una serie de registros que se utilizan para llevar a cabo la ejecución de instrucciones, estos registros se denominan registros de propósito especial. Los registros de propósito especial son de 8 tipos: los registros cs, ds, ss, es, fs y gs se incluyen en los registros de segmento. Estos registros contienen hasta seis selectores de segmento.
 CS (registro de segmento de código):
CS (registro de segmento de código):
Un registro de 16 bits llamado segmento de código (CS) contiene la dirección de una sección de 64 KB junto con las instrucciones de la CPU. Todos los accesos a las instrucciones a las que hace referencia un registro de puntero de instrucción (IP**) los realiza la CPU utilizando el segmento CS. Los cambios directos al registro de CS no son posibles. Cuando se utilizan las instrucciones de salto lejano, llamada lejana y retorno lejano, el registro CS se actualiza automáticamente.
DS (registro de segmento de datos):
Un segmento de 64 KB de datos de programa se direcciona mediante un registro de 16 bits denominado segmento de datos. El procesador por defecto cree que el segmento de datos contiene toda la información referida por los registros generales (AX, BX, CX y DX) y los registros de índice (SI, DI). Los comandos POP y LDS se pueden usar para modificar directamente el registro DS.
SS (registro de segmento de pila):
Un registro de 16 bits llamado segmento de pila contiene la dirección de un segmento de 64 KB con una pila de software. La CPU por defecto cree que el segmento de pila contiene toda la información referida por los registros de puntero de pila (SP) y puntero base (BP). La instrucción POP permite la modificación directa del registro SS.
ES (registro de segmento adicional):
Un registro de 16 bits llamado segmento adicional contiene la dirección de un segmento de 64 KB, que generalmente contiene datos de programa. En las instrucciones de manipulación de cadenas, la CPU asume por defecto que el registro DI se refiere al segmento ES. Los comandos POP y LES se pueden usar para actualizar directamente el registro ES.
FS (registro de segmento de archivo):
Los registros FS no tienen un propósito predeterminado por la CPU; en cambio, el sistema operativo que los ejecuta les da un propósito. En los procesos de Windows, FS se usa para apuntar al bloque de información de subprocesos (TIB).
GS (registro de segmento de gráficos):
El registro GS se usa en Windows de 64 bits para apuntar a estructuras definidas por el sistema operativo. Los núcleos del sistema operativo utilizan con frecuencia GS para acceder a la memoria específica de subprocesos. Windows emplea el registro GS para controlar la memoria específica de subprocesos. Para acceder a la memoria específica de la CPU, el kernel de Linux emplea GS. Un puntero a un almacenamiento local de subprocesos, o TLS, se usa con frecuencia como GS.
IP_ (Instruction Pointer register):
Los registros CS e IP_ son utilizados por el 8086 para acceder a las instrucciones. El número de segmento de la siguiente instrucción se almacena en el registro CS, mientras que el desplazamiento se almacena en el registro IP_. Cada vez que se ejecuta una instrucción, la IP_ se modifica para apuntar a la siguiente instrucción. La IP_ no puede ser modificada directamente por una instrucción, a diferencia de otros registros; una instrucción puede no tener la IP_ como su operando.

Conociendo los registros donde se almacena la memoria, solo necesitamos los comandos para empezar a programar en Ensamblador.

El tamaño de los Archivos (En argot informático: Peso).
¿Cuánto ocupará un documento formado por 1000 caracteres? Pues muy sencillo ¡1000 bytes!.
Como podemos observar, cuantos más caracteres, más ocupará el documento.
El Byte es la unidad básica de almacenamiento en informática (como el metro es de la longitud). Nos sirve para saber lo que ocupa un documento o cualquier programa (instrucciones que tendrá el programa).
Puedo saber cuantos bytes tiene un documento o lo que es lo mismo, cuantos bytes necesitaré para almacenarlo en algún sitio externo.
Como esta unidad es muy pequeña se suelen utilizar múltiplos de ella:
- 1 Bit (Corresponde a un 1 o 0 en código binario)
- 1 Nibble = 4 bits (Medio Byte)
- 1 Byte (B) = 8 bits (una letra, un número o un espacio en blanco en un documento)
- 1 Kilobyte (KB) = 1024 bytes
- 1 Megabyte (MB) = 1024 Kilobytes
- 1 Gigabyte (GB) = 1024 Megabytes
- 1 Terabyte (TB) = 1024 Gigabytes
- 1 Petabyte (PB) = 1024 Terabytes
- 1 Exabyte (EB) = 1024 Petabytes
- 1 Zettabyte (ZB) = 1024 Exabytes
- 1 Yottabyte (YB) = 1024 Zettabytes
- 1 Brontobyte (BB) = 1024 Yottabytes
Por ejemplo: un documento que ocupa 1 MB estará formado por 1024 números, letras, símbolos o espacios en blanco.
Llegados a este punto muchos os preguntareis, ¿porqué un kilobyte son 1024 bytes y no 1000?.
la respuesta no es sencilla y ha dado mucho que hablar entre las comunidades científicas y los ingenieros informáticos. El problema esta cuando intentamos normalizar o estandarizar algo que matemáticamente es imposible.
Al trabajar los sistemas informáticos en sistema binario, trabajamos con potencias de 2, entonces la secuencia de múltiplos de 2 seria la siguiente:
1 byte, 2 bytes, 4 bytes, 8 bytes, 16 bytes, 32, bytes, 64 bytes, 128 bytes, 256 bytes, 512 bytes y 1024 bytes
(Observareis la similitud con algunos componentes informáticos como las memorias RAM, los pendrives o las tarjetas SD).
El prefijo kilo hace referencia al sistema decimal (múltiplos de 10) y serian 1000 unidades.
En realidad el prefijo aceptado por la comunidad científica seria el “kibibyte” = 1024 bytes, pero la estandarización en la informática e ingeniería es esencial, por lo que se ha promovido por parte de estos, la utilización del prefijo “kilo” aunque este sea científicamente incorrecto.
Otra unidad muy usada en informática es la velocidad de transmisión de datos. Unidad usada para medir la velocidad a la que se mandan datos de un ordenador a otro en una red de ordenadores (por ejemplo velocidad internet), o la velocidad a la que se envían los datos de una parte a otra del ordenador.
La unidad de velocidad de transmisión de datos (bytes) de un sitio a otro se expresará en Bytes/segundo (B/s) MB/s o GB/s.
¡OJO! En algunas ocasiones se representa por bits/s en lugar de bytes/s (sobre todo en Internet) En este caso se diferencia por que la abreviatura es b (minúscula) en lugar de la B (mayúscula) usada para los bytes: ejemplo Mb/s (megabits por segundo). “Es una unidad 8 VECES MENOR que la anterior”.
Una vez hemos conocido el lenguaje de las maquinas, vamos a conocer como hablan entre ellas.
Encapsulado de datos y la pila de protocolo TCP/IP

El paquete es la unidad de información básica que se transfiere a través de una red. El paquete básico se compone de un encabezado con las direcciones de los sistemas de envío y recepción, y un cuerpo, o carga útil, con los datos que se van a transferir. Cuando el paquete se transfiere a través de la pila de protocolo TCP/IP, los protocolos de cada capa agregan o eliminan campos del encabezado básico. Cuando un protocolo del sistema de envío agrega datos al encabezado del paquete, el proceso se denomina encapsulado de datos. Asimismo, cada capa tiene un término diferente para el paquete modificado, como se muestra en la figura siguiente.
Figura 1–1 Transferencia de un paquete a través de la pila TCP/IP


Esta sección resume el ciclo de vida de un paquete. El ciclo de vida empieza cuando se ejecuta un comando o se envía un mensaje, y finaliza cuando la aplicación adecuada del sistema receptor recibe el paquete.
Capa de aplicación: el origen de la comunicación
El recorrido del paquete empieza cuando un usuario en un sistema envía un mensaje o ejecuta un comando que debe acceder a un sistema remoto. El protocolo de aplicación da formato al paquete para que el protocolo de capa de transporte adecuado (TCP o UDP) pueda manejar el paquete.
Supongamos que el usuario ejecuta un comando rlogin para iniciar sesión en el sistema remoto, tal como se muestra en la Figura 1–1. El comando rlogin utiliza el protocolo de capa de transporte TCP. TCP espera recibir los datos con el formato de un flujo de bytes que contiene la información del comando. Por tanto, rlogin envía estos datos como flujo TCP.
Capa de transporte: el inicio del encapsulado de datos
Cuando los datos llegan a la capa de transporte, los protocolos de la capa inician el proceso de encapsulado de datos. La capa de transporte encapsula los datos de aplicación en unidades de datos de protocolo de transporte.
El protocolo de capa de transporte crea un flujo virtual de datos entre la aplicación de envío y la de recepción, que se identifica con un número de puerto de transporte. El número de puerto identifica un puerto, una ubicación dedicada de la memoria par recibir o enviar datos. Además, la capa de protocolo de transporte puede proporcionar otros servicios, como la entrega de datos ordenada y fiable. El resultado final depende de si la información se maneja con los protocolos TCP, SCTP o UDP.
Segmentación TCP
TCP se denomina a menudo protocolo “orientado a la conexión” porque TCP garantiza la entrega correcta de los datos al host de recepción. La Figura 1–1 muestra cómo el protocolo TCP recibe el flujo del comando rlogin. A continuación, TCP divide los datos que se reciben de la capa de aplicación en segmentos y adjunta un encabezado a cada segmento.
Los encabezados de segmento contienen puertos de envío y recepción, información de orden de los segmentos y un campo de datos conocido como suma de comprobación. Los protocolos TCP de ambos hosts utilizan los datos de suma de comprobación para determinar si los datos se transfieren sin errores.
Establecimiento de una conexión TCP
TCP utiliza segmentos para determinar si el sistema de recepción está listo para recibir los datos. Cuando el protocolo TCP de envío desea establecer conexiones, envía un segmento denominado SYN al protocolo TCP del host de recepción. El protocolo TCP de recepción devuelve un segmento denominado ACK para confirmar que el segmento se ha recibido correctamente. El protocolo TCP de envío emite otro segmento ACK y luego procede al envío de los datos. Este intercambio de información de control se denomina protocolo de tres vías.
Paquetes UDP
UDP es un protocolo “sin conexiones“. A diferencia de TCP, UDP no comprueba los datos que llegan al host de recepción. En lugar de ello, UDP da formato al mensaje que se recibe desde la capa de la aplicación en los paquetes UDP. UDP adjunta un encabezado a cada paquete. El encabezado contiene los puertos de envío y recepción, un campo con la longitud del paquete y una suma de comprobación.
El proceso UDP de envío intenta enviar el paquete a su proceso UDP equivalente en el host de recepción. La capa de aplicación determina si el proceso UDP de recepción confirma la recepción del paquete. UDP no requiere ninguna notificación de la recepción. UDP no utiliza el protocolo de tres vías.
Capa de Internet: preparación de los paquetes para la entrega
Los protocolos de transporte TCP, UDP y SCTP transfieren sus segmentos y paquetes a la capa de Internet, en la que el protocolo IP los maneja. El protocolo IP los prepara para la entrega asignándolos a unidades denominadas datagramas IP. A continuación, el protocolo IP determina las direcciones IP para los datagramas, para que se puedan enviar de forma efectiva al host de recepción.
Datagramas IP

IP adjunta un encabezado IP al segmento o el encabezado del paquete, además de la información que agregan los protocolos TCP o UDP. La información del encabezado IP incluye las direcciones IP de los hosts de envío y recepción, la longitud del datagrama y el orden de secuencia del datagrama. Esta información se facilita si el datagrama supera el tamaño de bytes permitido para los paquetes de red y debe fragmentarse.
Dirección IP

Una dirección IP es una dirección única que identifica a un dispositivo en Internet o en una red local. IP significa “protocolo de Internet”, que es el conjunto de reglas que rigen el formato de los datos enviados a través de Internet o la red local.
En esencia, las direcciones IP son el identificador que permite el envío de información entre dispositivos en una red. Contienen información de la ubicación y brindan a los dispositivos acceso de comunicación. Internet necesita una forma de diferenciar entre distintas computadoras, enrutadores y sitios web. Las direcciones IP proporcionan una forma de hacerlo y forman una parte esencial de cómo funciona Internet.
Una dirección IP es una cadena de números separados por puntos. Las direcciones IP se expresan como un conjunto de cuatro números, por ejemplo, 192.158.1.38. Cada número del conjunto puede variar de 0 a 255. Por lo tanto, el rango completo de direcciones IP va desde 0.0.0.0 hasta 255.255.255.255.
Tipos de direcciones IP

Hay diferentes categorías de direcciones IP, y en cada categoría, diferentes tipos.
Direcciones IP
Cada individuo o empresa con un plan de servicio de Internet tendrá dos tipos de direcciones IP: sus direcciones IP privadas y su dirección IP pública. Los términos “pública” y “privada” se relacionan con la ubicación de la red, es decir, una dirección IP privada se utiliza dentro de una red, mientras que una pública se utiliza fuera de ella.
Direcciones IP privadas
Cada dispositivo que se conecta a tu red de Internet tiene una dirección IP privada. Esto incluye computadoras, teléfonos y tablets, pero también cualquier dispositivo que pueda conectarse mediante Bluetooth, como los altavoces, impresoras o televisores inteligentes. Con el creciente Internet de las cosas, la cantidad de direcciones IP privadas que tienes en casa probablemente está aumentando. El enrutador necesita una forma de identificar estos artículos por separado y muchos necesitan una forma de reconocerse entre sí. Por lo tanto, tu enrutador genera direcciones IP privadas que son identificadores únicos para cada dispositivo que los diferencian dentro la red.
Direcciones IP públicas
Una dirección IP pública es la dirección principal asociada a toda la red. Si bien cada dispositivo conectado tiene su propia dirección IP, también se incluyen en la dirección IP principal de la red. Como se describió anteriormente, tu ISP proporciona la dirección IP pública de tu enrutador. Normalmente, los ISP tienen un gran conjunto de direcciones IP que distribuyen a sus clientes. Tu dirección IP pública es la dirección que todos los dispositivos fuera de tu red de Internet utilizarán para reconocer tu red.
Las direcciones IP públicas se presentan de dos formas: dinámica y estática.
Direcciones IP dinámicas
Las direcciones IP dinámicas cambian de forma automática y con regularidad. Los ISP compran un gran grupo de direcciones IP y las asignan automáticamente a sus clientes. De forma periódica, reasignan y devuelven las direcciones IP más antiguas al grupo para que las utilicen otros clientes. La explicación detrás de esta estrategia es generar ahorros para el ISP. Automatizar el movimiento regular de las direcciones IP significa que no es necesario realizar acciones específicas para restablecer la dirección IP de un cliente, por ejemplo, si se muda de casa. También existen beneficios de seguridad, ya que una dirección IP cambiante facilita a los delincuentes el pirateo de la interfaz de red.
Direcciones IP estáticas
Por el contrario, las direcciones IP estáticas son siempre las mismas. Una vez que la red asigna una dirección IP, esta permanece igual. La mayoría de las personas y empresas no necesitan una dirección IP estática, pero para las empresas que planean alojar su propio servidor, es fundamental tener una. Esto se debe a que una dirección IP estática garantiza que los sitios web y las direcciones de correo electrónico vinculados tengan una dirección IP constante, lo que es vital si desea que otros dispositivos puedan encontrarlos de manera predecible en la Web.
Lo que nos lleva al siguiente punto, que es los dos tipos de direcciones IP para sitios web.
Redes, Subredes y la mascara de Red

Las direcciones IPv4 como 192.168.0.1 son realmente solo representaciones decimales de cuatro bloques binarios.
Cada bloque consta de 8 bits, y representa números del rango 0-255. Debido a que los bloques son grupos de 8 bits, cada bloque es conocido como un octeto. Y como hay cuatro bloques de 8 bits, cada dirección IPv4 es de 32 bits.
Por ejemplo, así es como luce la dirección IP 172.16.254.1 en binario:

Para convertir una dirección IP entre sus formas decimal y binaria, puedes usar esta tabla:

La tabla de arriba representa un octeto (8 bits).
Ahora digamos que quieres convertir la dirección IP 168.210.225.206. Todo lo que necesitas es separar la dirección en cuatro bloques (168, 210, 225, y 206), y convertir cada uno a binario usando la tabla de arriba.
Recuerda que en binario, 1 es el equivalente a “encendido” y 0 es “apagado”. Así que para convertir el primer bloque, 168, a binario, solo comienza al inicio de la tabla y coloca un 1 o 0 en esa celda hasta que obtengas una suma de 168.
Por ejemplo:
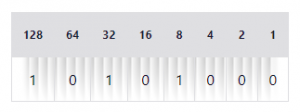
128 + 32 + 8 = 168, que en binario es 10101000.
Si haces esto para el resto de los bloques, obtendrás 10101000.11010010.11100001.11001110.
¿Qué es la división en Subredes (subnetting)?
Si miras la tabla de arriba, pareciera como si el número de direcciones IP fuera prácticamente ilimitado. Después de todo, hay casi 4.2 mil millones de posibles direcciones IPv4 disponibles.
Pero si piensas en cuánto ha crecido el internet, y cuántos dispositivos más están conectados en estos tiempos, puede que no te sorprendas saber que ya hay una escasez de direcciones IPv4.
Debido a que la escasez fue reconocida hace años, los desarrolladores idearon una forma de dividir una dirección IP en redes más pequeñas llamadas subredes.
Este proceso, llamado división en subredes (subnetting), usa la sección host de la dirección IP para descomponerla en esas redes más pequeñas o subredes.
Generalmente, una dirección IP está compuesta por bits de red y bits de host:
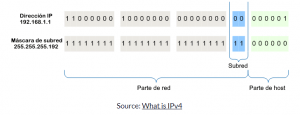
Por lo general, la división en subredes hace dos cosas: nos brinda una manera de dividir las redes en subredes, y permite que los dispositivos determinen si otro dispositivo/dirección IP está en la misma red local o no.
Una buena manera de pensar en la división de subredes es imaginar tu red doméstica inalámbrica.
Sin la división en subredes, cada dispositivo conectado a internet necesitaría su propia dirección IP única.
Pero como tienes un enrutador inalámbrico, tan solo necesitas una dirección IP para tu enrutador. Esta dirección IP externa o pública es usualmente manejada de manera automática, y es asignada por tu proveedor de servicios de internet (ISP, por sus siglas en inglés, Internet Service Provider).
Luego, cada dispositivo conectado a ese enrutador tiene su propia dirección IP privada o interna:
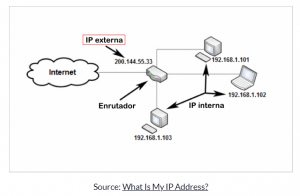
Ahora, si tu dispositivo con la dirección IP interna 192.168.1.101 quiere comunicarse con otro dispositivo, usará la dirección IP del otro dispositivo y la máscara de subred.
La combinación de las direcciones IP y la máscara de subred permite que el dispositivo en 192.168.1.101 averigüe si el otro dispositivo está en la misma red (como el dispositivo en 192.168.1.103), o en una red completamente diferente en algún otro lugar en línea.
Curiosamente, la dirección IP externa asignada a tu enrutador por tu Proveedor de Servicio de Internet (ISP) es probablemente parte de una subred, la cual podría incluir muchas otras direcciones IP para casas o negocios cercanos. Y justo como las direcciones IP internas, también necesita una máscara de subred para funcionar.
Cómo funcionan las máscaras de subred
Las máscaras de subred funcionan como una especie de filtro para una dirección IP. Con una máscara de subred, los dispositivos pueden mirar una dirección IP y determinar cuáles partes son los bits de red y cuáles son los bits de host.
Luego usando esas cosas, se puede determinar la mejor manera de comunicarse para esos dispositivos.
Si has estado hurgando en la configuración de red de tu enrutador o computadora, es probable que hayas visto este número:255.255.255.0.
Si así fue, has visto una máscara de subred muy común para redes domésticas simples.
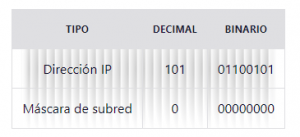
Tal como las direcciones IPv4, las máscaras de subred son de 32 bits. Y justo como se convierte una dirección IP a binario, puedes hacer lo mismo con una máscara de subred.
Por ejemplo, aquí está nuestra tabla de antes:

Ahora convirtamos el primero octeto, 255:
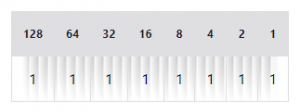
Muy fácil, ¿cierto? Así que cualquier octeto que es 255 es solo 11111111 en binario. Esto significa que 255.255.255.0 es en realidad 11111111.11111111.11111111.00000000 en binario.
Ahora veamos la máscara de subred y la dirección IP juntas y calculemos cuáles partes de la dirección IP son los bits de red y los bits de host.
Aquí están las dos en decimal y binario:

Con las dos dispuestas de esta forma, es fácil separar 192.168.0.101 en bits de red y bits de host.
Cada que un bit en una máscara de subred binaria es 1, entonces el mismo bit en una dirección IP binaria pertenece a la red, no al host.
Como el octeto 255 es 11111111 en binario, todo ese octeto en la dirección IP es parte de la red. Así que los primeros tres octetos, 192.168.0, son la porción de red de la dirección IP, y 101 es la porción de host.
En otras palabras, si el dispositivo en 192.168.0.101 quiere comunicarse con otro dispositivo, usando la máscara de subred sabe que cualquier cosa con la dirección IP 192.168.0.xxx se encuentra en la misma red local.
Otra manera de expresar esto es con un ID de red, que es solo la porción de red de la dirección IP. Así que el ID de red de la dirección 192.168.0.101 con la máscara de subred 255.255.255.0 es 192.168.0.0.
Y es lo mismo para los otros dispositivos en la red local (192.168.0.102, 192.168.0.103, y así).
¿Qué Significa CIDR y Qué es la Notación CIDR?
Son las siglas en inglés de Classless Inter-Domain Routing, Enrutamiento Entre Dominios Sin Clases, y es usado en IPv4, y más recientemente, en enrutamiento IPv6.
CIDR fue introducido en 1993 como una manera de ralentizar el uso de direcciones IPv4, las cuales se estaban acabando rápidamente bajo el viejo sistema de direccionamiento IP con clase sobre el que se construyó internet por primera vez.
CIDR abarca un par de conceptos importantes.
El primero es el Subenmascaramiento de Longitud Variable (Variable Length SubMasking, VLSM, por sus siglas en inglés), que básicamente permitió a los ingenieros de redes crear subredes dentro de subredes. Y esas subredes podían ser de diferentes tamaños, por lo que habrían pocas direcciones IP sin usar.
El segundo concepto importante que CIDR introdujo fue la notación CIDR.
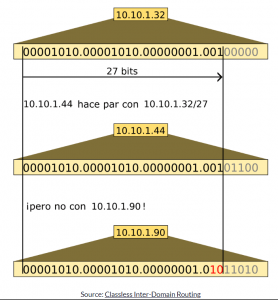
La notación CIDR es en realidad solo una abreviatura de la máscara de subred , y representa el número de bits disponibles para la dirección IP. Por ejemplo, el /24 en 192.168.0.101/24 es equivalente a la dirección IP 192.168.0.101 y la máscara de subred 255.255.255.0.
Cómo Calcular la Notación CIDR
Para determinar la notación CIDR para una máscara de subred dada, todo lo que necesitas es convertir la máscara de subred a binario, y luego contar los unos o dígitos en “encendido”. Por ejemplo:
Debido a que hay tres octetos de unos, hay 24 bits en “encendido”, lo que significa que la notación CIDR es /24.
Puedes escribirlo de cualquier manera, pero estarás de acuerdo que /24 es mucho más fácil de escribir que 255.255.255.0.
Esto generalmente se hace con una dirección IP, así que demos un vistazo a la misma máscara de subred con una dirección IP:
Los primeros tres octetos de la máscara de subred son todos bits de “encendido”, lo que significa que los mismos tres octetos en la dirección IP son todos bits de red.
Echemos un vistazo al último cuarto octeto con más detalle:
En este caso, debido a que todos los bits para este octeto en la máscara de subred están en “apagado”, podemos estar seguros de que todos los bits correspondientes a este octeto en la dirección IP son parte del host.
Cuando escribes en notación CIDR es común hacerlo con la ID de red. Por lo que la notación CIDR para la dirección IP 192.168.0.101 con una máscara de subred 255.255.255.0 es 192.168.0.0/24.
Direccionamiento IP Con Clase
Ahora que ya hemos repasado algunos ejemplos básicos de división en subredes y CIDR, veamos lo que es conocido como direccionamiento IP con clase.
Antes de que la división en subredes fuera desarrollada, todas las direcciones IP caían dentro de una clase en particular:
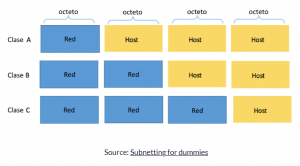
Toma en cuenta que hay direcciones IP de clase D y E, pero entraremos a detalle en eso más adelante.
Las direcciones IP con clase dieron a los ingenieros de redes una manera de proveer un rango de direcciones IP válidas a diferentes organizaciones.
Hubo muchos problemas con este enfoque que eventualmente llevó a la división en subredes. Pero antes de llegar ahí, veamos de manera más cercana a las diferentes clases.
Direcciones IP de Clase A
Para las direcciones IP de Clase A, el primer octeto (8 bits / 1 byte) representa el ID de red, y los tres octetos restantes (24 bits / 3 bytes) son el ID de host.
Las direcciones IP de Clase A van desde 1.0.0.0 hasta 127.255.255.255, con una máscara predeterminada 255.0.0.0 (u /8 en CIDR).
Esto significa que el direccionamiento Clase A puede tener un total de 128 (27) redes y 16,777,214 (224-2) direcciones utilizables por red.
Además, toma en cuenta que el rango desde 127.0.0.0 al 127.255.255.255 dentro del rango de la Clase A, está reservado para la dirección de bucle invertido del host (vea RFC5735).
Direcciones IP de Clase B
Para las direcciones IP de Clase B, los primeros dos octetos (16 bits / 2 bytes) representan el ID de red y los dos octetos restantes (16 bits / 2 bytes) son el ID de host.
Las direcciones IP de Clase B van desde 128.0.0.0 hasta 191.255.255.255, con una máscara predeterminada 255.255.0.0 (o /16 en CIDR).
El direccionamiento Clase B puede tener 16,384 (214) direcciones de red y 65,534 (216) direcciones utilizables por red.
Direcciones IP de Clase C
Para direcciones IP de Clase C, los primeros tres octetos (24 bits / 3 bytes) representan el ID de red, y el último octeto (8 bits / 1 bytes) es el ID de host.
Las direcciones IP de Clase C van desde 192.0.0.0 hasta 223.255.255.255, con una máscara predeterminada 255.255.255.0 (o /24 en CIDR).
La Clase C se traduce a 2,097,152 (221) redes y 254 (28-2) direcciones utilizables por red.
Direcciones IP de Clase D y Clase E
Las últimas dos clases son la Clase D y la Clase E.
Las direcciones IP de Clase D están reservadas para multidifusiones. Ellas ocupan el rango desde 224.0.0.0 hasta 239.255.255.255.
Las direcciones IP de Clase E son experimentales, y son cualquiera arriba de 240.0.0.0.
El Problema de las Direcciones IP Con Clase
El problema principal con las direcciones IP con clase es que no fue algo eficiente, y llevaba a tener muchas direcciones IP desperdiciadas.
Por ejemplo, imagina que eres parte de una organización grande en aquel entonces. Tu compañía tiene 1,000 empleados, lo que significa que caería dentro de la clase B.
Pero si miras arriba, verás que una red de clase B puede soportar hasta 65,534 direcciones utilizables. Eso es mucho más de lo que tu organización necesitaría, incluso si cada empleado tuviera múltiples dispositivos con una dirección única.
Y no había manera de que tu organización volviera a la clase C – no habría suficientes direcciones IP utilizables.
Así que mientras las direcciones IP con clase fueron usadas en el momento en el que las direcciones IPv4 se volvieron una norma, rápidamente se hizo evidente que sería necesario un mejor sistema para garantizar que no usaríamos todas las ~4.200 millones de direcciones utilizables.
Las direcciones IP con clase no han sido usadas desde que fueron reemplazadas por CIDR en 1993, y son mayormente estudiadas para entender la arquitectura temprana de internet, y el por qué la división en subredes es importante.
Capa de vínculo de datos: ubicación de la estructuración
Los protocolos de capa de vínculo de datos, como PPP, colocan el datagrama IP en una estructura. Estos protocolos adjuntan un tercer encabezado y un pie de página para crear una estructura del datagrama. El encabezado de la estructura incluye un campo de comprobación de la redundancia cíclica (CRC) que comprueba si se producen errores al transferir la estructura por el medio de red. A continuación, la capa del vínculo de datos transfiere la estructura a la capa física.
Capa de red física: ubicación de envío y recepción de estructuras
La capa de red física del host de envío recibe las estructuras y convierte las direcciones IP en las direcciones de hardware adecuadas para el medio de red. A continuación, la capa de red física envía la estructura a través del medio de red.
Administración del paquete por parte del host de recepción
Cuando el paquete llega al host de recepción, se transfiere a través de la pila de protocolo TCP/IP en el orden inverso al envío. La Figura 1–1 ilustra esta ruta. Asimismo, cada protocolo del host de recepción filtra la información de encabezado que adjunta al paquete su equivalente en el host de envío.
Tiene lugar el siguiente proceso:
- La capa de red física recibe el paquete con el formato de estructura. La capa de red física procesa la CRC del paquete y luego envía la misma estructura a la capa del vínculo de datos.
- La capa del vínculo de datos comprueba que la CRC de la estructura sea correcta y filtra el encabezado de la estructura y la CRC. Finalmente, el protocolo del vínculo de datos envía la estructura a la capa de Internet.
- La capa de Internet lee la información del encabezado para identificar la transmisión. A continuación, la capa de Internet determina si el paquete es un fragmento. Si la transmisión está fragmentada, el protocolo IP reúne los fragmentos en el datagrama original. A continuación, IP filtra el encabezado de IP y transfiere el datagrama a los protocolos de capa de transporte.
- La capa de transporte (TCP, SCTP y UDP) lee el encabezado para determinar qué protocolo de capa de aplicación debe recibir los datos. A continuación, TCP, SCTP o UDP filtra el encabezado relacionado. TCP, SCTP o UDP envía el mensaje o el flujo a la aplicación de recepción.
- La capa de aplicación recibe el mensaje. A continuación, la capa de aplicación lleva a cabo la operación que solicita el host de envío.
Ya tenemos un indico de como las maquinas se comunican entre ellas, ahora vamos a ver que redes de comunicación utilizan.
REDES E INTERNET
CONEXIÓN EN RED
Dicho de forma general, se designara una red como una unión de varias unidades de dispositivos, ya sea el ordenador, una impresora u otros componentes del sistema.
La forma más elemental es la conexión de dos ordenadores. Si estos ordenadores esta en el mismo edificio se le llamara:
LAN “RED DE ÁREA LOCAL”.

Las características de una red local son:
- Aumento de productividad.
- Reducción de los costes de los equipos.
- Aumento del nivel de comunicación.
- Simplicidad de gestión.
A las redes que están compuestas por unidades que se encuentran instaladas en diferentes edificios, ciudades e incluso en diferentes países se les llama:
WAN o “RED DE ÁREA AMPLIA”.

En principio existen dos componentes esenciales:
Las tarjetas de red.
Las conexiones de cables con ellas relacionadas
Pero existen otros componentes especiales sin los cuales la red no está preparada para su aplicación:
El fileserver: Ninguna red puede estar sin este componente: es el cerebro de todas las redes. Se encarga de todas las funciones de mando que se produzcan dentro de una red.
El printserver: Se le asignara funciones de trabajo, como las tareas de impresión. No es indispensable en el establecimiento de una red.
La estación de trabajo: Todos los ordenadores conectados a una red, son denominados estaciones de trabajo. Se facilitara desde las estaciones de trabajo al usuario; el acceso a los periféricos de una red.
CLASES DE REDES:
WAN : Una Red de Área Amplia (Wide Area Network o WAN, del inglés). Es una red de Ordenadores gran tamaño, generalmente dispersa en un área metropolitana, a lo largo de un país o incluso a nivel planetario. La red WAN más amplia es Internet. Las redes WAN a parte del cable pueden usar sistemas de comunicación vía satélite o de radio.
Fue la aparición de los portátiles y los PDA la que trajo el concepto de redes inalámbrica y un poco de confusión por parecerse las palabras WAN y WLAN al mundo de las redes inalámbricas.

WLAN
(en inglés; Wireless Local Area Network) es un sistema de comunicación de datos inalámbrico , muy utilizado como alternativa a las redes LAN cableadas o como extensión de éstas. Utiliza tecnología de radiofrecuencia que permite mayor movilidad a los usuarios al minimizar las conexiones cableadas.
A nivel de redes domesticas el router tiene varias luces (Ethernet, WLAN, Encendido, y Alerta). La luz WLAN si está encendida nos indica la activación de las comunicaciones inalámbricas en el router. Si la luz WLAN está apagada, necesitamos leer el manual de instrucciones del fabricante y ver cómo se activa la WLAN o comunicaciones inalámbricas en el router. Generalmente se activa en el router con un botón que indica reset.
LAN :
Una red de área local, es la interconexión de varios ordenadores y periféricos de no más de 100 Metros. Su aplicación más extendida es la interconexión de ordenadores personales y estaciones de trabajo en oficinas, fábricas, etc., para compartir recursos e intercambiar datos y aplicaciones. En definitiva, permite que dos o más máquinas se comuniquen por cable o inalámbrico.

WIRELESS :
Son dispositivos que soportan comunicaciones inalámbricas, en las que se utilizan modulación de ondas electromagnéticas, radiaciones o medios ópticos. Estás se propagan por el espacio vacío sin medio físico que comunique cada uno de los extremos de la transmisión.
Para las redes domesticas son todos aquellos dispositivos catalogados como WIRELESS en las tiendas de informática para poder conectar vía red LAN inalámbrica con otros dispositivos WIRELESS y con la WLAN del router de Internet.
WIFI :
Es una abreviatura de Wireless Fidelity, es un conjunto de estándares para redes inalámbricas basado en las especificaciones IEEE 802.11.
Existen diversos tipos de Wi-Fi, y son los siguientes:
Los estándares IEEE 802.11be IEEE 802.11g disfrutan de una aceptación internacional debido a que la banda de 2.4 GHz está disponible casi universalmente, con una velocidad de hasta 11 Mbps y 54 Mbps, respectivamente (Dispositivos wireless).
En la actualidad ya se maneja también el estándar IEEE 802.11a, conocido como WIFI 5, que opera en la banda de 5 GHz para las tecnologías (Bluetooth, microondas, ZigBee, WUSB). Su enlace es algo menor que el de los estándares que trabajan a 2.4 GHz (un 10% a mayor frecuencia, menor alcance).
Todo lo explicado sirve para conectar todos los dispositivos entre sí, sin necesidad de utilizar cables entre ellos. Dicha tecnología nos da una cobertura y movilidad de dispositivos total en nuestra casa.
Pero sigamos aprendiendo más sobre las abreviaturas, ahora nos centramos en los tipos de acceso entre dispositivos y encriptaciones de datos.
SSID (Service Set Identifier) :
Es para identificar y nombrar la red WAN. Cuando activamos la WLAN en el router, después configuramos sus parámetros y uno de ellos es el nombre de la red inalámbrica a identificar por nuestros dispositivos (PC y Puntos de Acceso).
Las redes inalámbricas pueden verse desde el exterior, sólo buscando los SSID existentes en el aire, podemos conectar un Ordenador con nuestra propia red inalámbrica, o con otras redes vecinas cercanas a nuestra red LAN.
Para garantizar la no conexión de otros dispositivos externos en nuestras redes inalámbricas, existe la autentificación y aceptación de dichos dispositivos a la red LAN y WLAN del router. Si no estás bien autentificado, la Red inalámbrica rechazara dicho dispositivo y no lo dejara entrar a la red LAN.
Para complicar aún más todo este mundillo , existen diferentes métodos de autentificación (PSK, IEEE 802.X, Por Usuario, Certificados y libres)
Las autentificaciones (IEEE 802.1X y Certificados) son para empresas y no las vamos a explicar en dicho artículo.
Vamos a explicar las utilizadas en redes domesticas y son:
PSK : Claves pre-compartidas :Un método que realiza claves creadas manualmente y estáticas, utiliza el que configura la red inalámbrica para identificarse a un Ordenador PSK. También funciona como encriptación.
Por Usuario : Configurar nuestra red inalámbrica con un nombre de usuario y contraseña.
Libre : Existe la posibilidad de entrar a la red sin autentificaciones por parte de ningún dispositivo a la red inalámbrica. Todos vosotros pensaréis que dicha opción nunca se utilizara, pero estáis muy equivocados. Cuando estamos configurando la red inalámbrica y existen problemas de conectabilidad, es necesario durante un cierto tiempo abrir la red para poder ir descartando opciones y poder averiguar dónde está el problema de conexión entre los dispositivos.
Una vez identificado el tipo de autentificación a utilizar, cambiamos la configuración de la política de seguridad y la encriptación de la información.
WEP (Protocolo Equivalente Alámbrico): es un código de seguridad usado para codificar los datos transmitidos sobre una red inalámbrica. El WEP tiene tres configuraciones: Off (ninguna seguridad), 64-bit (seguridad débil), 128-bit (seguridad algo mejor). El WEP usa cuatro claves de cifrado que pueden ser cambiados periódicamente para hacer más difícil la interceptación del tráfico. Todos los dispositivos en la red deben usar la misma codificación (claves).
WPA (Acceso Protegido Wi-Fi) es un nivel más alto de seguridad que el WEP que combina la codificación y la autentificación para crear un nivel inquebrantable de protección.
WPA-PSK (clave compartida en WPA) es configurada para cada dispositivo de red, para que los paquetes enviados sobre una red inalámbrica sean codificados usando TKIP (Protocolo de Integridad de Clave Temporal). o AES (Estándar de cifrado avanzado).
Dirección MAC : Es un control de acceso de medios que cada adaptador, cada tarjeta de interfaz de red, ha grabado en el hardware. Es único, los puntos de acceso o el router pueden tener una tabla de estas direcciones y permitir que se conecte únicamente esta tarjeta de interfaz de red.
INTERNET
(o, también, la internet) es un conjunto descentralizado de redes de comunicación interconectadas que utilizan la familia de protocolos TCP/IP, lo cual garantiza que las redes físicas heterogéneas que la componen formen una red lógica única de alcance mundial. Sus orígenes se remontan a 1969, cuando se estableció la primera conexión de computadoras, conocida como ARPANET, entre tres universidades en California (Estados Unidos).

Uno de los servicios que más éxito ha tenido en internet ha sido la World Wide Web (WWW o la Web), hasta tal punto que es habitual la confusión entre ambos términos.
La WWW es un conjunto de protocolos que permite, de forma sencilla, la consulta remota de archivos de hipertexto. Esta fue un desarrollo posterior (1990) y utiliza internet como medio de transmisión.
Existen, por tanto, muchos otros servicios y protocolos en internet, aparte de la Web: el envío de correo electrónico (SMTP), la transmisión de archivos (FTP y P2P), las conversaciones en línea (IRC), la mensajería instantánea y presencia, la transmisión de contenido y comunicación multimedia —telefonía (VoIP), televisión (IPTV)—, los boletines electrónicos (NNTP), el acceso remoto a otros dispositivos (SSH y Telnet) o los juegos en línea.
El uso de Internet creció rápidamente en el hemisferio occidental desde la mitad de la década de 1990, y desde el final de la década en el resto del mundo. En los 20 desde 1995, el uso de Internet se ha multiplicado por 100, cubriendo en 2015 a la 3ª parte de la población mundial. La mayoría de las industrias de comunicación, incluyendo telefonía, radio, televisión, correo postal y periódicos tradicionales están siendo transformadas o redefinidas por el Internet. Permitiendo el nacimiento de nuevos servicios como email, telefonía por internet, televisión por Internet, música digital, y video digital.
Las industrias de publicación de periódicos, libros y otros medios impresos se están adaptando a la tecnología de los sitios web, o están siendo reconvertidos en blogs, web feeds o agregadores de noticias online (p. ej., Google Noticias). Internet también ha permitido o acelerado nuevas formas de interacción personal a través de mensajería instantánea, foros de Internet, y redes sociales como Facebook. El comercio electrónico ha crecido exponencialmente para tanto grandes cadenas como para pequeños y mediana empresa o nuevos emprendedores, ya que permite servir a mercados más grandes y vender productos y servicios completamente en línea. Relaciones business-to-business y de servicios financieros en línea en Internet han afectado las cadenas de suministro de industrias completas.
![]()
Continuar con la Seguridad Informática 
![]()